|
I am a Staff Research Scientist at Meta GenAI , working on foundation models. Previously, I was a Research Scientist at XR Tech in Meta Reality Labs working on 3D Scene Understanding. Prior to joining Meta, I did my Ph.D. at TUM Visual Computing Group headed by Prof. Matthias Niessner, where I work on Computer Vision and 3D Scene Understanding. During my Ph.D., I did an internship at Facebook AI Research (FAIR) with Prof. Saining Xie and Dr. Benjamin Graham on 3D representation and data-efficient learning. Before that, I obtained my master at RWTH Computer Vision Group headed by Prof. Bastian Leibe, where I studied on Computer Vision and Machine Learning. I am interested in research and applications on Generative Models on Image/Video/3D, as well as 3D Computer Vision, e.g. 3D Reconstruction, VR/AR, Robotics and Autonomous Driving etc. Email / Google Scholar / Github / Twitter / Linkedin |
|
|
|

|
Xichen Pan, Satya Narayan Shukla†, Aashu Singh, Zhuokai Zhao, Shlok Kumar Mishra, Jialiang Wang, Zhiyang Xu, Jiuhai Chen, Kunpeng Li, Felix Juefei-Xu, Ji Hou†, Saining Xie† arxiv, 2025 arxiv / project page / code / bibtex †Equal advising Introducing MetaQueries, a minimal recipe for building state-of-the-art unified multimodal understanding (text output) and generation (pixel output) models. |

|
Cong Wei, Bo Sun, Haoyu Ma, Ji Hou, Felix Juefei-Xu, Zecheng He, Xiaoliang Dai, Luxin Zhang, Kunpeng Li, Tingbo Hou, Animesh Sinha, Peter Vajda, Wenhu Chen Neural Information Processing Systems (NeurIPS), 2025 (Spotlight Presentation) arxiv / project page / hf page / bibtex MoCha enables, for the first time, Multi-character Conversations with Turn-based Dialogue generation, pushing the boundaries of automated filmmaking. |

|
Xu Ma, Peize Sun, Haoyu Ma, Hao Tang, Chih-Yao Ma, Jialiang Wang, Kunpeng Li, Xiaoliang Dai, Yujun Shi, Xuan Ju, Yushi Hu, Artsiom Sanakoyeu, Felix Juefei-Xu, Ji Hou, Junjiao Tian, Tao Xu, Tingbo Hou, Yen-Cheng Liu, Zecheng He, Zijian He, Matt Feiszli, Peizhao Zhang, Peter Vajda, Sam Tsai, Yun Fu arxiv, 2025 arxiv / project page / bibtex For the first time, we push the boundary of AR text-to-image generation to a resolution of 2048x2048 with gratifying generation performance. |

|
Hongjie Wang, Chih-Yao Ma, Yen-Cheng Liu, Ji Hou, Tao Xu, Jialiang Wang, Felix Juefei-Xu, Yaqiao Luo, Peizhao Zhang, Tingbo Hou, Peter Vajda<, Niraj K. Jha, Xiaoliang Dai Computer Vision and Pattern Recognition (CVPR), 2025 arxiv / project page / bibtex We propose a Linear-complexity text-to-video Generation (LinGen) framework whose cost scales linearly in the number of pixels. For the first time, LinGen enables high-resolution minute-length video generation on a single GPU without compromising quality |

|
Feng Liang, Haoyu Ma, Zecheng He, Tingbo Hou, Ji Hou, Kunpeng Li, Xiaoliang Dai, Felix Juefei-Xu, Samaneh Azadi, Animesh Sinha, Peizhao Zhang, Peter Vajda, Diana Marculescu Computer Vision and Pattern Recognition (CVPR), 2025 arxiv / project page / bibtex We present Movie Weaver to support multi-concept video personalization. |
|
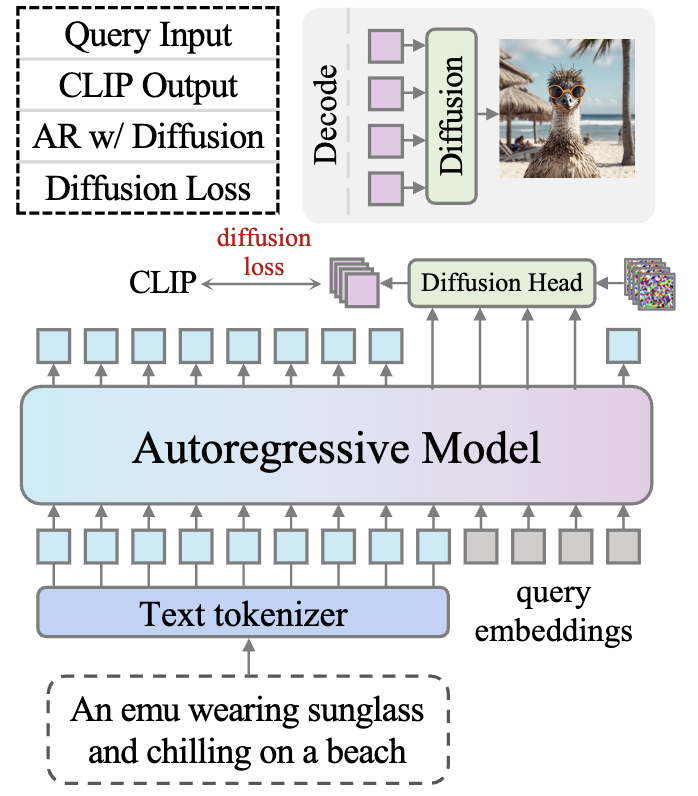
Contributor Tech Report, 2025 arxiv / blog / bibtex We built native image generation in Llama 4 with a diffusion head predicting CLIP features that are used as a condition of a diffusion model to decode images. |

|
Core Contributor Technical Report, 2024 arxiv / project / bibtex Movie Gen is a cast of Meta media foundation models that generate high-quality, 1080p HD videos with different aspect ratios and synchronized audio. |

|
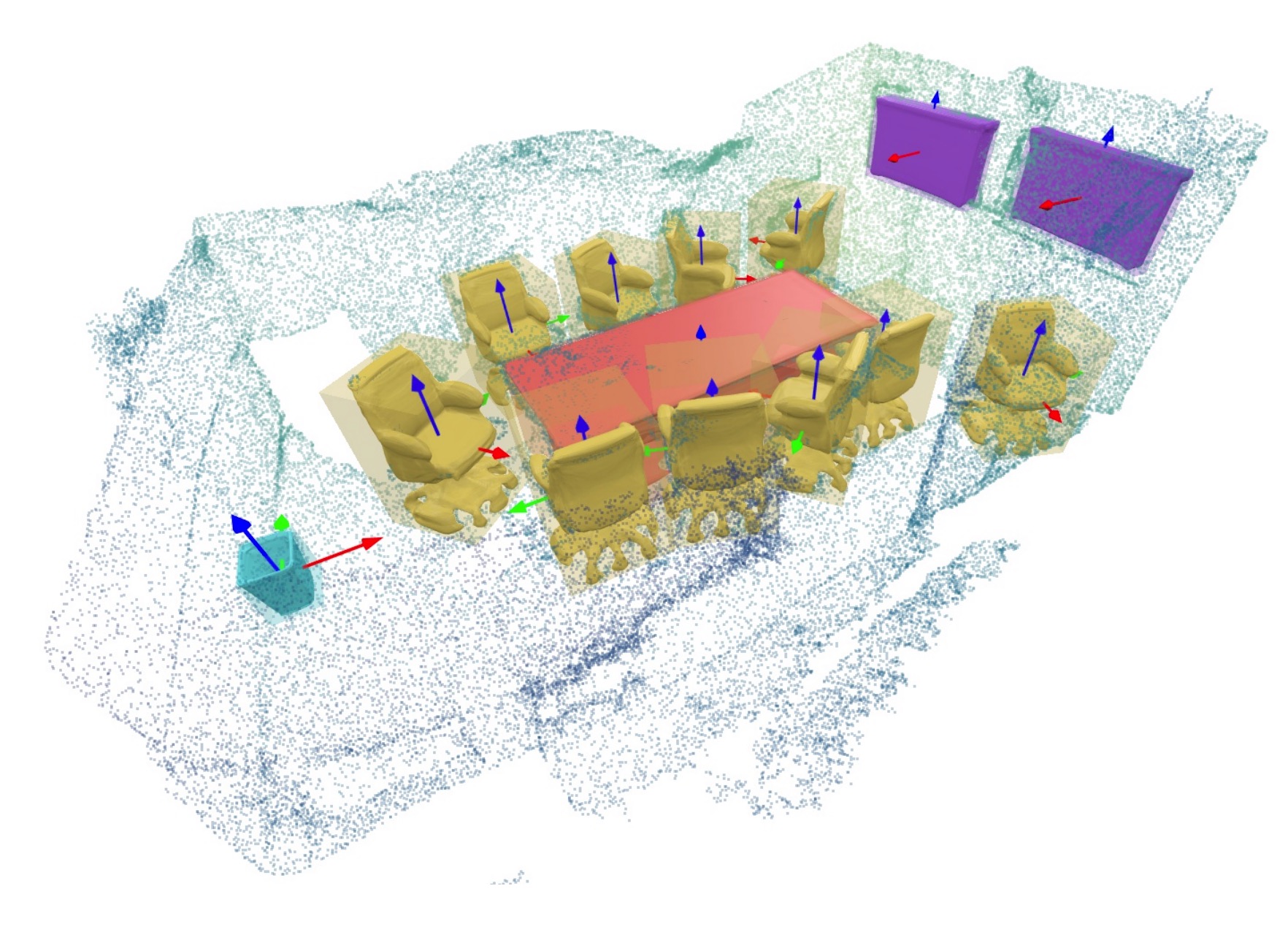
Jonas Schult, Sam Tsai, Lukas Höllein, Bichen Wu, Jialiang Wang, Chih-Yao Ma, Kunpeng Li, Xiaofang Wang, Felix Wimbauer, Zijian He, Peizhao Zhang, Bastian Leibe, Peter Vajda, Ji Hou Computer Vision and Pattern Recognition (CVPR), 2024 arxiv / project page / video / bibtex Given a textual description of the overall room style and a rough 3D room layout based on 3D semantic bounding boxes, our method called ControlRoom3D creates diverse and globally plausible 3D room meshes which align well with the room layout. |

|
Felix Wimbauer, Bichen Wu, Edgar Schoenfeld, Xiaoliang Dai, Ji Hou, Zijian He, Artsiom Sanakoyeu, Peizhao Zhang, Sam Tsai, Jonas Kohler, Christian Rupprecht, Daniel Cremers, Peter Vajda, Jialiang Wang Computer Vision and Pattern Recognition (CVPR), 2024 arxiv / project page / bibtex Our block caching technique allows us to avoid these unnecessary computations, therefore speeding up inference by a factor of 1.5x-1.8x while maintaining image quality. |
|
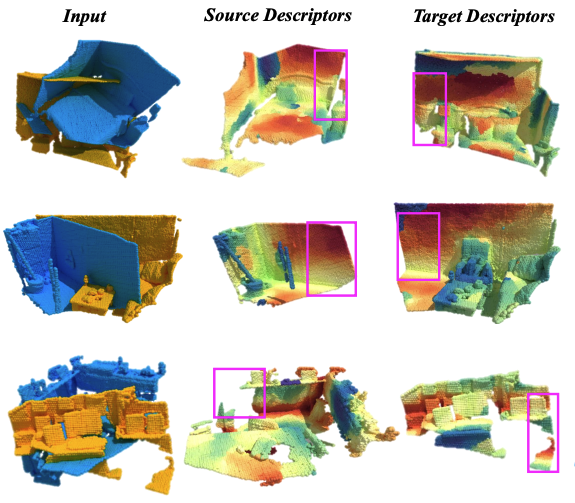
Hao Yu, Ji Hou, Zheng Qin, Mahdi Saleh, Ivan Shugurov, Kai Wang, Benjamin Busam, Slobodan Ilic IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2024 paper / arxiv / bibtex Successful point cloud registration relies on accurate correspondences established upon powerful descriptors. However, existing neural descriptors either leverage a rotation-variant backbone whose performance declines under large rotations, or encode local geometry that is less distinctive. To address this issue, we introduce RIGA to learn descriptors that are Rotation-Invariant by design and Globally-Aware. |

|
Core Contributor Technical Report, 2024 arxiv / project / bibtex Emu is the Meta text-to-image media foundation model. |

|
Chenfeng Xu, Bichen Wu, Ji Hou *, Sam Tsai, Ruilong Li, Jialiang Wang, Wei Zhan Zijian He, Peter Vajda, Kurt Keutzer, Masayoshi Tomizuka International Conference on Computer Vision (ICCV), 2023 paper / bibtex / project / code * Corresponding author NeRF-Det is a novel method for 3D detection with posed RGB images as input. Our method makes novel use of NeRF in an end-to-end manner to explicitly estimate 3D geometry, thereby improving 3D detection performance. |
|
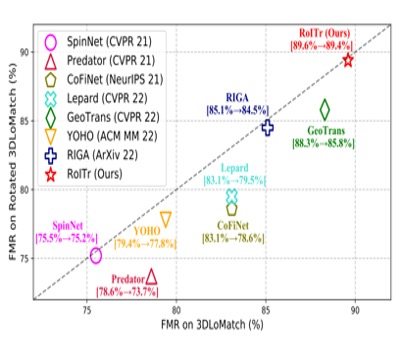
Hao Yu, Zheng Qin, Ji Hou, Mahdi Saleh, Dongsheng Li, Benjamin Busam, Slobodan Ilic Computer Vision and Pattern Recognition (CVPR), 2023 paper / bibtex / code We introduce RoITr, a Rotation-Invariant Transformer to cope with the pose variations in the point cloud matching task. On the challenging 3DLoMatch benchmark, RoITr surpasses the existing methods by at least 13 and 5 percentage points in terms of the Inlier Ratio and the Registration Recall, respectively |

|
Ji Hou, Xiaoliang Dai, Zijian He, Angela Dai, Matthias Nießner Computer Vision and Pattern Recognition (CVPR), 2023 paper / video / bibtex We demonstrate the Mask3D is particularly effective in embedding 3D priors into the powerful 2D ViT backbone, enabling improved representation learning for various scene understanding tasks, such as semantic segmentation, instance segmentation and object detection. |

|
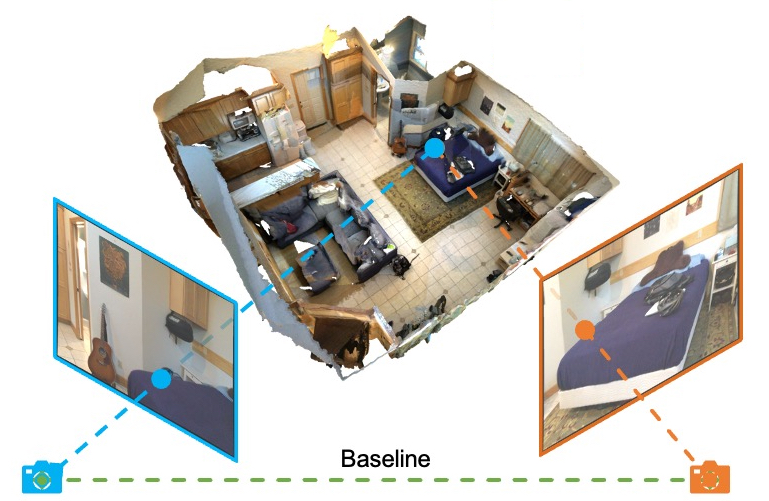
Yu Zhang, Junle Yu, Xiaolin Huang, Wenhui Zhou, Ji Hou European Conference on Computer Vision (ECCV), 2022 paper / video / bibtex / poster / code We introduce PCR-CG: a novel 3D point cloud registration module explicitly embedding the color signals into geometry representation. With our designed 2D-3D projection module, the pixel features in a square region centered at correspondences perceived from images are effectively correlated with point cloud representations. |
|
Ji Hou, Saining Xie, Benjamin Graham, Angela Dai, Matthias Nießner International Conference on Computer Vision (ICCV), 2021 paper / video / bibtex / project / code Recent advances in 3D perception have shown impressive progress in understanding geometric structures of 3D shapes and even scenes. Inspired by these advances in geometric understanding, we aim to imbue image-based perception with representations learned under geometric constraints. |

|
Manuel Dahnert, Ji Hou, Matthias Nießner Angela Dai Advances in Neural Information Processing System (NeurIPS), 2021 paper / video / bibtex / project / code Inspired by 2D panoptic segmentation, we propose to unify the tasks of geometric reconstruction, 3D semantic segmentation, and 3D instance segmentation into the task of panoptic 3D scene reconstruction -- from a single RGB image, predicting the complete geometric reconstruction of the scene in the camera frustum of the image, along with semantic and instance segmentations. |

|
Ji Hou, Benjamin Graham, Matthias Nießner, Saining Xie Computer Vision and Pattern Recognition (CVPR), 2021 (Oral Presentation) paper / video / bibtex / project / code / benchmark Our study reveals that exhaustive labelling of 3D point clouds might be unnecessary; and remarkably, on ScanNet, even using 0.1% of point labels, we still achieve 89% (instance segmentation) and 96% (semantic segmentation) of the baseline performance that uses full annotations. |
|
Yinyu Nie, Ji Hou, Xiaoguang Han, Matthias Nießner Computer Vision and Pattern Recognition (CVPR), 2021 paper / video / bibtex / code In this work, we introduce RfD-Net that jointly detects and reconstructs dense object surfaces directly from raw point clouds. Instead of representing scenes with regular grids, our method leverages the sparsity of point cloud data and focuses on predicting shapes that are recognized with high objectness. |
|
Ji Hou, Angela Dai, Matthias Nießner Computer Vision and Pattern Recognition (CVPR), 2020 paper / video / bibtex / project This paper introduces the task of semantic instance completion: from an incomplete, RGB-D scan of a scene, we detect the individual object instances comprising the scene and jointly infer their complete object geometry. |

|
Ji Hou, Angela Dai, Matthias Nießner Computer Vision and Pattern Recognition (CVPR), 2019 (Oral Presentation) paper / video / bibtex / project / code We introduce 3D-SIS, a novel neural network architecture for 3D semantic instance segmentation in commodity RGB-D scans. The core idea of our method is to jointly learn from both geometric and color signal, thus enabling accurate instance predictions. |
|
|
|
|
|
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)
ACM Transactions on Multimedia Computing Communications and Applications (TOMM) International Journal of Computer Vision (IJCV) ISPRS Journal of Photogrammetry and Remote Sensing IEEE Robotics and Automation Letters (RA-L) IEEE Transactions on Image Processing (TIP) Pattern Recognition Letters Neurocomputing Computers & Graphics Special Interest Group on Computer Graphics and Interactive Techniques (SIGGRAPH) Conference on Computer Vision and Pattern Recognition (CVPR) International Conference on Computer Vision (ICCV) European Conference on Computer Vision (ECCV) International Conference on Machine Learning (ICML) Neural Information Processing Systems (NeurIPS) International Conference on Learning Representations (ICLR) International Conference on Robotics and Automation (ICRA) Association for the Advancement of Artificial Intelligence (AAAI) International Joint Conference on Artificial Intelligence (IJCAI) ACM Multimedia (ACMMM) |
|
|
|
|
|
Credits: Jon Barron |